
原文:Conditional Generative Adversarial Nets
收录:2014
GAN的一个重要优势就是不需要计算马尔科夫链(Markov chains),只需要通过反向传播算法就可以获得梯度,在学习过程中也不需要进行推断(inference),一系列的因素和相互作用就可以被轻易地加入到模型当中。
除此之外,CGAN还可以产生最先进的对数似然估计和现实样本。在非条件的生成模型中,我们没法控制生成样本的类型。然而,通过给模型增加额外的信息,我们可以引导模型生成方向。
本文展示如何构建CGAN。我们还展示CGAN在两个数据集上的结果,一个是以类别标签作为条件的MNIST数据集;还有一个是建立在MIR Flickr 25,000 dataset上的多模态学习(multi-modal learning)。
Q1: 监督神经网络(尤其是卷积网络)取得了巨大成功,但是将这种模型应用到具有非常多的预测输出类别数的问题上仍然面临挑战。
Q2: 如今大部分工作都主要集中在研究输入到输出一对一的映射。对于一对多映射怎么办?
(比如说在图片标注问题上,对于一个图片可能对应多个标签,不同的人可能会使用不同的标签来描述这一幅image)
对第二个问题,有人采用类似的办法,在MIR Flickr 25,000 dataset上训练了一个深度玻兹曼机。
GAN包含生成模型G用来捕获数据分布,判别模型D估计样本来自data而不是G的概率。G和D都可以是非线性的映射函数,比如多层感知机模型。
为了学习到生成器关于data x 的分布pg,生成器G构建了一个从先验噪声概率分布pz(z)到数据空间的映射G(z;θg)。判别器D(x;θd)输出一个单一的标量,代表x来自训练样本而不是pg的概率。D与G同时训练。具体见生成对抗网络(一)GAN讲解。
如果 G 和 D 都基于一些额外的信息y的话,GAN可以扩展为一个条件模型CGAN,其中y可以是任何形式的辅助信息,比如说类别标签或者其他模式的数据。我们可以通过增加额外的输入层来将y同时输入 G 和 D来实施条件模型CGAN。
在生成器G中,噪声先验概率分布pz(z)和y被结合成一个连接隐藏表达式;在判别器D中,x和y被输入到判别函数(在本例中再次由MLP多层感知器体现)。
目标函数:
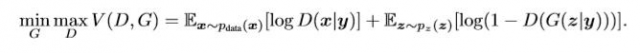
对抗网络结构:
本文链接:http://task.lmcjl.com/news/5584.html


