Paper:
Shmelkov, Konstantin, Cordelia Schmid, and Karteek Alahari. “How good is my GAN?.” ECCV-European Conference on Computer Vision. 2018.
文章提出了一种评价GAN的方法。
在GAN提出之后,评判GAN的生成效果一直是一个问题。最开始的时候用人眼去评判:即观察生成的样本是否与真实样本相似。但是对于不同GAN,却不好主观地去比较哪种方法生成的效果较好。所以需要定量的评测方法。
因此需要得到一种定量的评价指标。近几年Inception Score、Frechet Inception distance 、sliced Wasserstein distance(SWD)等评测指标也被提出用于评测GAN。
其中Inception Score表达式如下:
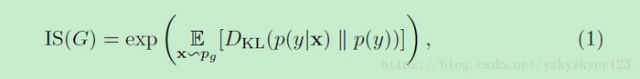
就是计算对于输入
很明显,它的缺点是没有将输出样本与ground truth样本进行比较。由此不能反映出生成的图像是否逼近真实图像。
它能反映的是仅仅是生成图像的多样性。
IS值越高越好。
FID越小越好。它将ground truth图像和生成图像(公式中用g表示)输入到Inception Net(公式中用下标r表示),根据它们倒数第二层提出的特征来计算:
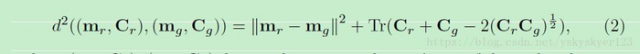
其中m表示均值,C表示协方差。
这种方法假设数据的分布为高斯分布,然后计算他们的均值和方差,再来求出FID值。缺点是1) 无法捕捉细微的变化; 2)根据FIS值的提高,无法判断判断是由GAN生成样本的多样性不足导致,还是由GAN生成样本与ground truth样本差异较大导致。
FS和FID均依赖于用ImageNet与训练的Inception Net。
SWD来自于Wasserstein GAN,又叫Earth-Mover(EM)距离。SWD的信息量低于文章提出的评价指标,后有实验为证。
GAN-train和GAN-test。
简单的说,所谓GAN-train就是用待评测的GAN生成的图片去训练分类网络,然后用训练好的网络对真实图片进行分类。GAN-train 反应的是生成图像的多样性。
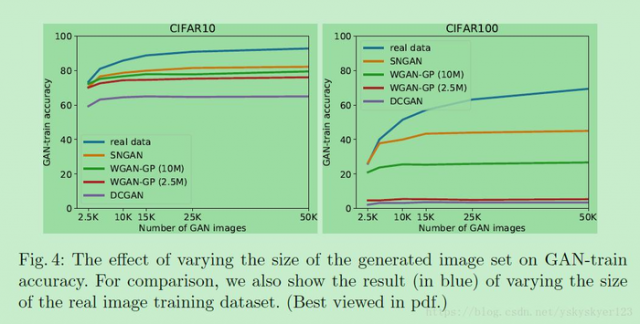
下面的曲线图横坐标是训练网络时使用GAN生成图片的数量,纵坐标是训练好的网络在测试时的准确率。
其中蓝色的曲线反映的是用真实图片来训练的情况,其它颜色曲线反映的是用不同GAN方法各自的情况。从图中我们发现SNGAN生成的样本对分类网络的训练有帮助,这证明SNGAN生成样本的多样性比较强,使得网络学习到了不同标签之间的差异。进而,在测试时,能够很好的区分不同物体。
所谓GAN-test,是指分类网络用真实的图片训练,测试时用GAN生成的图片来测试。
如果测试的结果与用真实图片来测试的结果少的不多,证明GAN生成图片与真实图片相似性高。
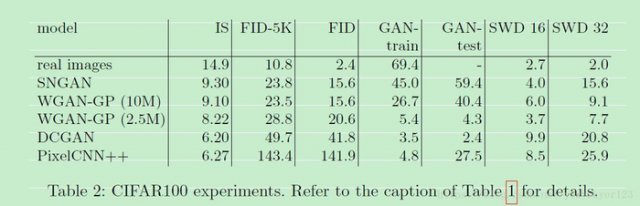
除此之外,文章用CIFAR10、CIFAR100、ImageNet数据集和SNGAN、WGAN、DCGAN、Pixel来验证GAN-train、GAN-test两种评价指标。
Table 2.表明SWD并不能很好的用来比较WGAN和其它GAN方法。
对于PixelCNN++,由于GAN-test比GAN-train高很多,可以看出该方法生成图片的多样性不足。
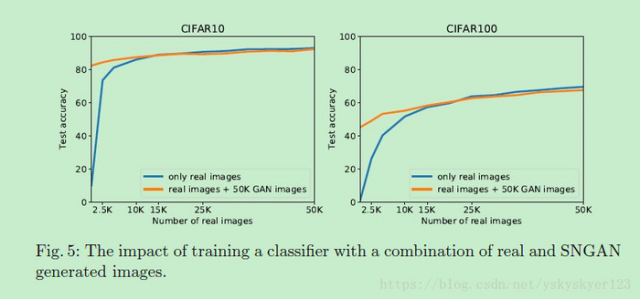
Fig. 5 中,橘色曲线表示的是用固定数量的真实图片+GAN生成图片来训练;蓝色的曲线表示的是用同样数量的真实图片来训练 。从中可以看出,在真实图片较少的情况下,GAN生成图片可以提升训练效果,证明了GAN生成图片的多样性。但是当真实图片达到一定数量之后,加入GAN生成图片反而降低了训练效果,这是因为GAN生成图片的多样性不如真实图片。
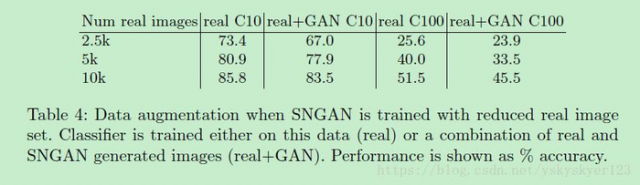
Table 4.同样也反映了上述的问题,当真实图片达到一定数量时,加入GAN生成图片反而会降低训练效果。
本文链接:http://task.lmcjl.com/news/5880.html


