
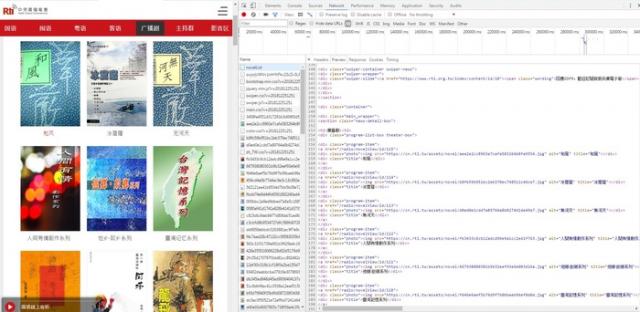
可以看到一个DIV下放一个广播剧的信息,包括名称和地址,第一步我们先收集所有广播剧的收听地址:
# 用requests的get方法访问
novel_list_resp = requests.get("这里放URL的地址")
# 利用上一步访问返回的结果生成一个BeautifulSoup对象
opera_soup = BeautifulSoup(novel_list_resp.text, "lxml")
# 获取所有class="program-item"的div
opera_soup.find_all("div", class_="program-item")
接着我们遍历这些div,获取每个广播剧的链接和名称:
# 找到div中的a标签,获取每个广播剧的链接
opera_link = domain + div.find("a").get('href')
# 获取每个广播剧的名称
title = div.find("div", class_="title").string
我们点击一个广播剧进去,在HTML中可以看到在ul中,每个li里都有一集的播放链接,并且是按顺序的。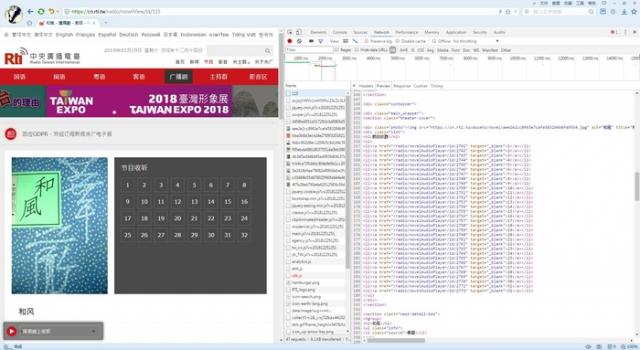
代码中我们继续用之前的方法访问单个广播剧地址,来获取剧集的list:
# 访问单个广播剧页面
novel_view_resp = requests.get(opera_link)
# 利用上一步访问返回的结果生成一个BeautifulSoup对象
view_soup = BeautifulSoup(novel_view_resp.text, "lxml")
# 首先定位h2标签,然后获取h2的下一个ul标签(直接找ul的话会找到其他的ul),然后获取所有a标签
list_a = view_soup.find('h2').find_next_sibling('ul').find_all('a')
# 接着遍历a标签,把每集的地址取出来
view_link = domain + a.get('href')
我们继续看一个单集的播放的HTML,source标签里就是最终的资源地址了,一个MP4文件: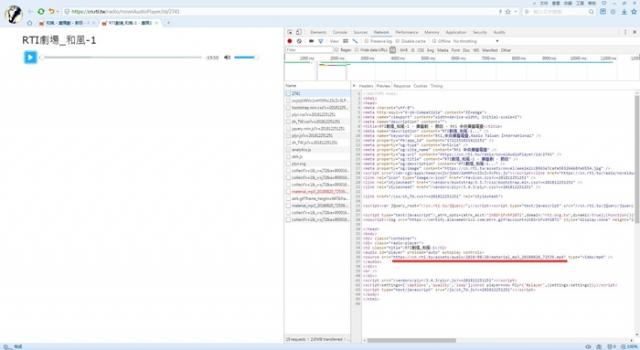
# 打开单集的播放页面
play_resp = requests.get(view_link)
play_soup = BeautifulSoup(play_resp.text, "lxml")
# 获取资源下载地址
src = play_soup.find('source').attrs['src']
现在我还不想下载,我希望先试听确认喜欢后再下载,所以我把下载地址存到一个txt里,一个广播剧存一个txt:
name = file_path + name + '.txt'
with open(name, 'wb') as f:
f.write(content)
由于编码问题,在文件最上加上以下代码:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
运行效果: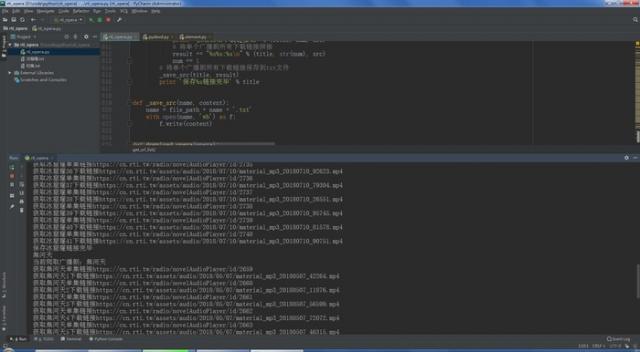
下载的MP4的代码: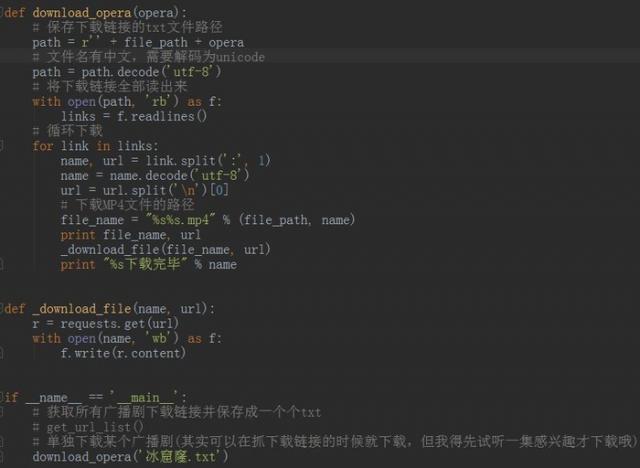
# 使用requests的get方法访问下载链接
r = requests.get(url)
# 将访问返回二进制数据内容保存为MP4文件
with open(name, 'wb') as f:
f.write(r.content)
最终的运行结果: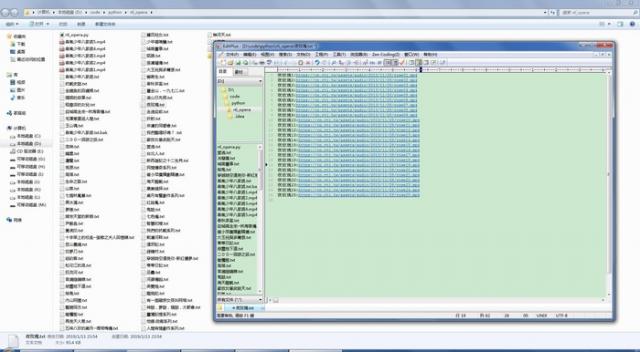
源码地址:https://github.com/songzhenhua/rti_opera/blob/master/rti_opera.py
BeautifulSoup参考地址:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#attributes
http://www.cnblogs.com/zhaof/p/6930955.html
---------------------------------------------------------------------------------
关注微信公众号即可在手机上查阅,并可接收更多测试分享~

本文链接:http://task.lmcjl.com/news/6625.html


